Main Body
5 Generating Synthetic Trail Camera Images with 3D Modelling & Animation in Blender
A.V. Ronquillo
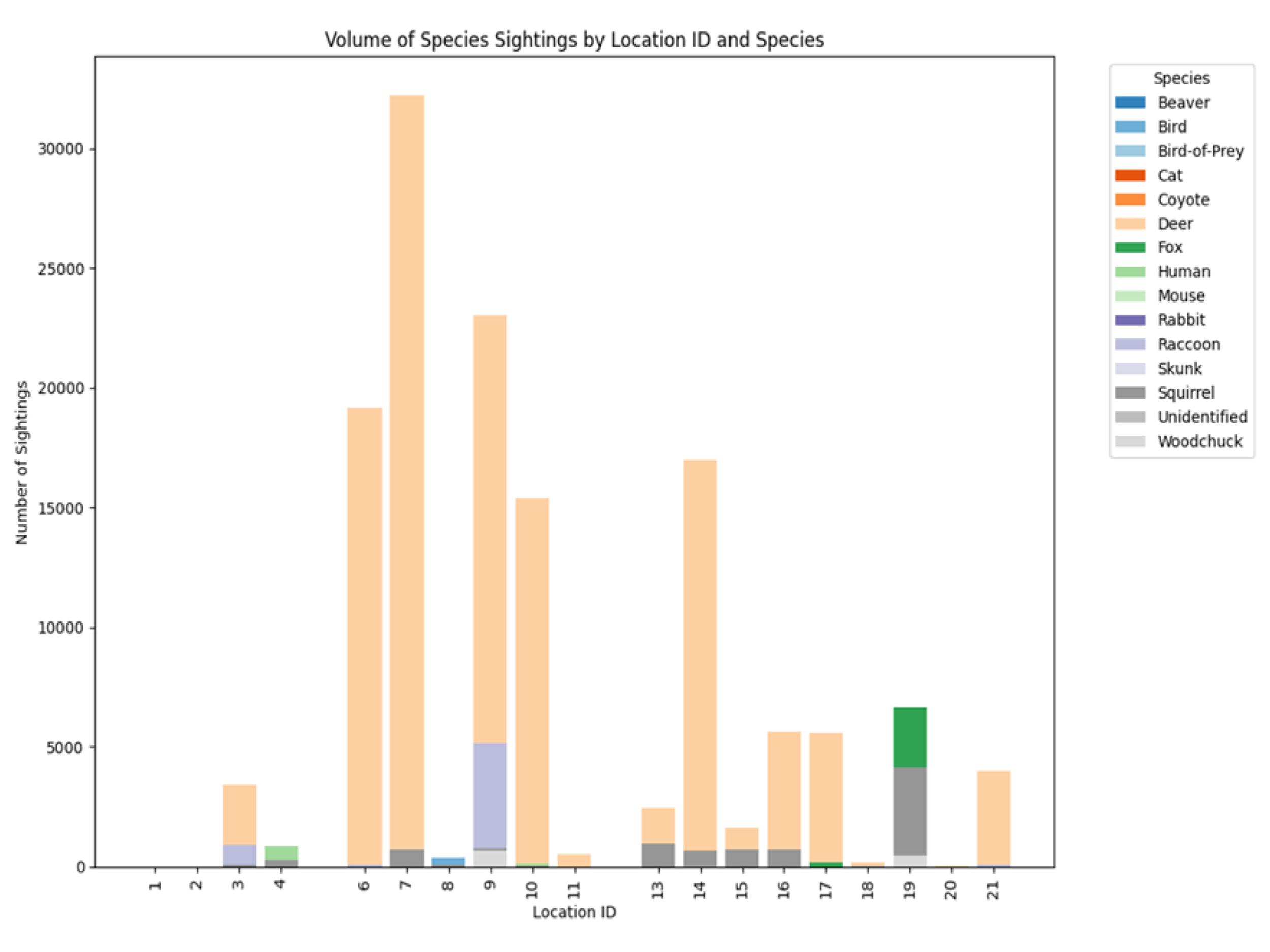
Imbalanced Data in Model Training
The Wild Winnipeg project contains a data imbalance in the sense that the dataset contains a large number of deer, raccoon, fox and squirrel images and a much smaller number of coyote, bird, rabbit and woodchuck images (figure 5.1). A classification model trained on this imbalanced dataset could be expected to identify the majority classes with greater precision than the minority classes because it encounters more examples of these images during its training[1]. The overall accuracy of classification thus declines when the model is trained using imbalanced data[2], and the classification model would create more accurate predictions if this imbalance was addressed.[3] Additionally, in other real-world applications, correctly identifying the minority classes can be quite crucial. For instance, in the clinical field, various medical image datasets suffer from the problem of imbalance because this issue of imbalance hampers the diagnostic detection of outliers or rare health care events.[4]
Achieving accuracy in classification thus requires that all classes are sufficiently well-represented in the training data; this is often not the case in real-world datasets.[5] Generating synthetic images is one powerful strategy for achieving balance in datasets. In the ‘Understanding Animals’ project, we explored various methods for generating images of underrepresented animal classes using diffusion models; these methods are described in the Stable Diffusion Jupyter Notebook. However, the strategy that we found most successful for generating synthetic images of animals was animating 3D animal models in Blender.
Assets & HDR Images in Blender
Blender is a free, open-source 3D creation suite used by artists, animators, game developers, and designers for modelling, animation, rendering, and video editing. A powerful software that allows for a high degree of agency in creative projects, Blender is appreciated for its community-driven attributes and built-in rendering engines. The engine used for generating synthetic images is “Cycles”, a high-quality and photorealistic rendering engine that is GPU-supported within Blender.
BlendSwap is a website where assets created in Blender can be shared and accessed by users. This website hosts 3D models and textures that can be freely downloaded, used, and modified based on conditions set by the creative licenses. The website has a wide range of categories, including foliage models and animal assets, that are relevant to the task of generating synthetic animal images. BlendSwap models were used to generate synthetic images of the squirrel, cat, bird, and fox classes as described below. These main animal models contain robust armatures and textures, and were sourced from BlendSwap’s community-driven collection of free, open-source assets (figure 5.2).

Similar to BlendSwap, Poly Haven is a website where model assets are offered for free under a variety of licenses. This platform provides textures, 3D models, and high dynamic range (HDR) image files. Various HDR images of natural environments are the main assets acquired from the “HDRI” category in Poly Haven. These streetview-like images provided a background environment and an immersive world setting for the 3D animal models (figure 5.3).

The process of generating synthetic animal images in Blender began by establishing the environment using HDR images. The HDR images can be imported and set as the ‘World’ of the Blender file, which is achieved by navigating to the Shader Editor in the interface. This ‘World’ setting is crucial because it allows users to integrate environmental textures that influence the scene’s background and lighting. These HDR images enhance the scene’s realism, which is vital for creating immersive and realistic environments. These images simulate a real-world environment and significantly contribute to the depth and realism of the rendered scenes.
Animating Animal Models through Rigging, Keyframes & Scene Configuration
In the domain of Blender animation, rigs, armatures, and keyframes are important concepts for facilitating realistic animations. An armature is a type of Blender object used to create a skeleton and consists of a hierarchical structure of ‘bones’. Armatures provide a framework that deforms a model’s mesh, allowing the creation of certain flexes and movements of bones.[6] Rigs are a more comprehensive setup that refers to the entire system used to animate a model, including the armature and other functional elements, allowing the animation process to become more manageable and versatile. Rigs incorporate control handles which simplify bone manipulation and the process of creating poses in an intuitive manner (figure 5.4). Rigs can also include constraints that restrict movement to specific axes or maintain relationships between bones, enforcing bone movement rules to ensure that animations are natural and realistic.[7]
Keyframes serve as markers that define the start and end points of an animation sequence. In between keyframes, Blender uses interpolation to generate smooth transitions, automatically calculating the intermediate frames that produce fluid motions.[8] Keyframes can be inserted into the Dope Sheet’s “Action Editor” where users can specify the values of properties such as position, rotation, and scale of bones at specific frames within the timeline.[9] This allows animators to create transitions between different states of the model, establishing the paths and movements that objects will follow over time.[10] Armatures, rigs, and keyframes are all fundamental aspects of successfully animating 3D models within Blender. These mechanisms streamline the animation workflow and provide a user-friendly interface for intuitively creating action sequences such as walking, running, or jumping. A helpful tutorial and cohesive documentation on how to use these Blender tools can be found in Blender’s official manual – Animation & Rigging.[11]
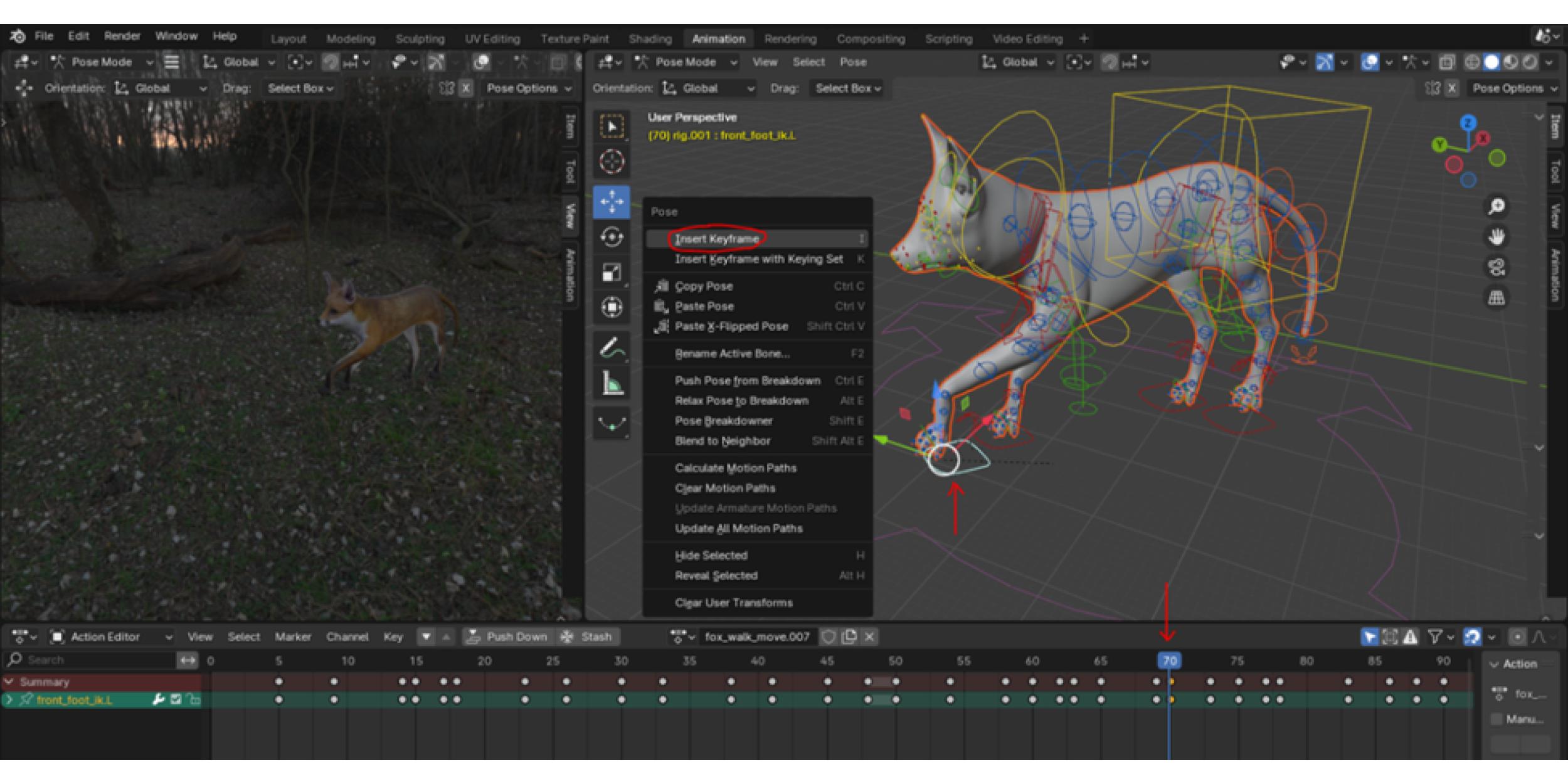
An important aspect of this workflow is the creation of variations within the animations. Blender’s versatile interface allows users to duplicate and modify existing actions, enabling the addition of diverse movements and behaviours. For instance, in addition to a basic walking animation, the walking movement can be copied as a new sequence and modified, allowing animators to incorporate head and neck movements that make the fox appear as though it is scanning its surroundings within the virtual world. This capability to create and manage multiple animation variations enriches the visual storytelling and realism of the synthetic images.
Synthesizing images also involves specifying a set of desired image attributes that should be considered for performing meaningful model training. The aim is to create a dataset that encompasses a wide range of scenarios, which concentrates on a single task within the Blender environment.[12] Therefore, the desired attributes revolve around visual diversity, movement realism, detailed models, and consistent resolution quality.[13] These attributes assist in creating the desired visual diversity and ensure that the classification model will learn from different contexts, making it more robust to real-world variability.[14]
When building synthetic image datasets, detailed 3D models and assets are essential. For animal models specifically, two key elements make them effective for training:
Realistic Surface Details: Models require intricate textures that accurately represent each animal species’ unique features, such as fur patterns, skin textures, and surface markings.[15] These detailed textures make the animals appear lifelike in rendered images, which is crucial when the animal is the main subject for image classification tasks.[16]
Accurate Anatomical Structure: The underlying bone structure, or skeletal rig, must be anatomically correct and detailed. This allows for natural, convincing movements and poses. When you pair accurate skeletons with properly modelled muscles and joints, you can generate a wide variety of realistic actions and positions.
Having both detailed textures and accurate anatomy in your training data helps machine learning models better understand animal poses, behaviours, and proportions.[17] This creates more diverse and effective synthetic datasets for computer vision tasks. The workflow involves creating 3D animal models in Blender that are both visually realistic on the surface and anatomically accurate underneath, then using these models to generate varied synthetic training images.
It is also important to consider the resolution and overall image quality of artificial images. There should be consistency in the quality and resolution of each animal class. For instance, renders of a fox model with detailed textures should have the same pixel quality as the images rendered with the cat model.[18] However, producing quality images comes with some challenges. High-quality renders can be time-consuming and require robust hardware resources. Using Blender to produce high-quality renders is highly time-intensive and may not be feasible when the goal is to create a thousand or more synthetic images in a limited time. This is particularly true for models with detailed surface details and armatures (figure 5.5). Balancing render quality with processing time requires optimization and compromise.[19] The quality of a synthetic dataset can be assessed not just by its resolution but also by its visual diversity and robust animal models. Therefore, it is important to achieve image quality through varied and diverse configurations of the animal in the virtual environment. The quality of synthetic images can also be improved by increasing the depth of fur, which has been shown to improve the classification performance of models trained on the synthetic image data.[20]

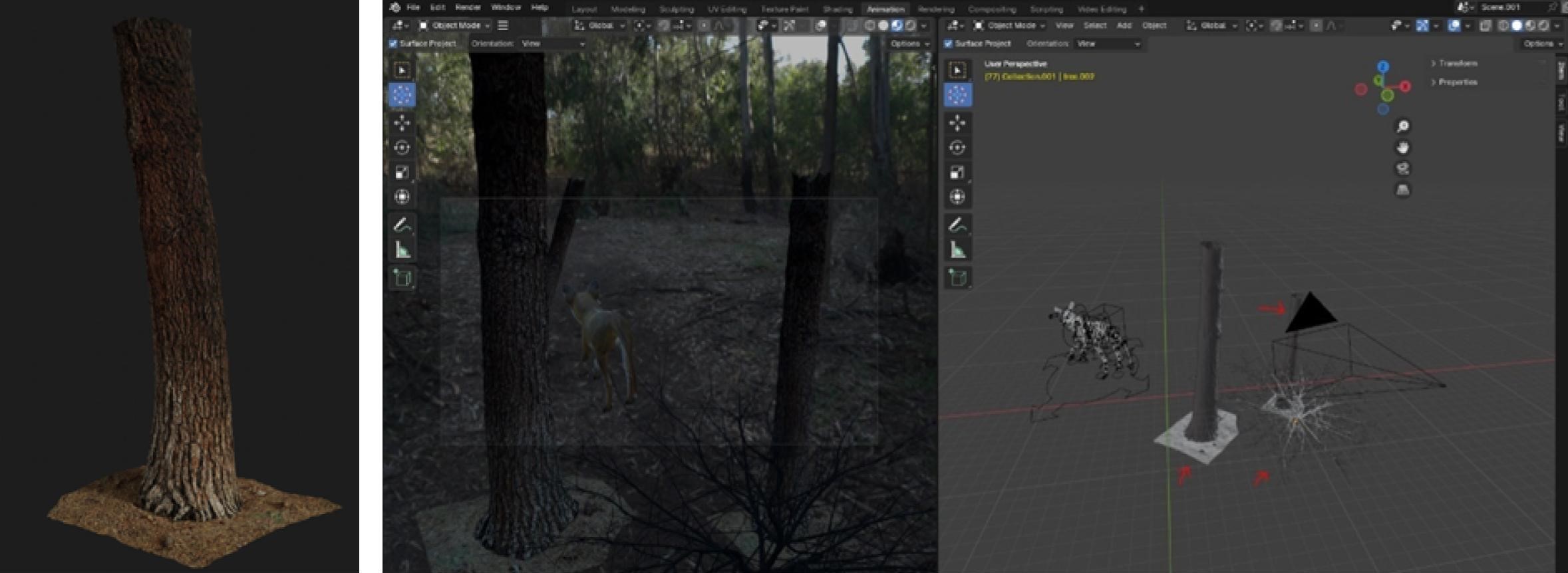
A diverse, high-quality set of synthetic images can also be achieved through intentional image framing. This involves setting up the camera and configuring the scene to capture the targeted visual outcome. The “3D Viewport” can be organized into a dual-view setup that allows users to efficiently adjust the models and ensure they align with the view of the camera (figure 5.6). In doing so, within the HDR World, the camera can be rotated and positioned at different angles to frame the foliage and animal models to create a desired perspective. In this manner, a wide range of positionings involving the foliage models, the animated animals, and the HDR background can be explored to create a diversity of final visual renders.
Night scenes can also be used to increase visual diversity of synthetic images (figure 5.7). Lighting is a critical element for rendering realistic nighttime images. Appropriate light sources are essential for achieving the desired aesthetic of trail camera images set at nighttime. The Object Data Properties panel can be navigated to adjust the qualities of light sources, including intensity (measured in watts), blend, bounces, and light radius. To replicate nighttime conditions, the output should be set to a Black and White (BW) format, which reflects the style of the real trail camera images from the original dataset. This methodology generates synthetic trail camera images that closely resemble nighttime images from the original dataset.

Establishing Render Output Properties in Blender for a Synthetic Images Dataset
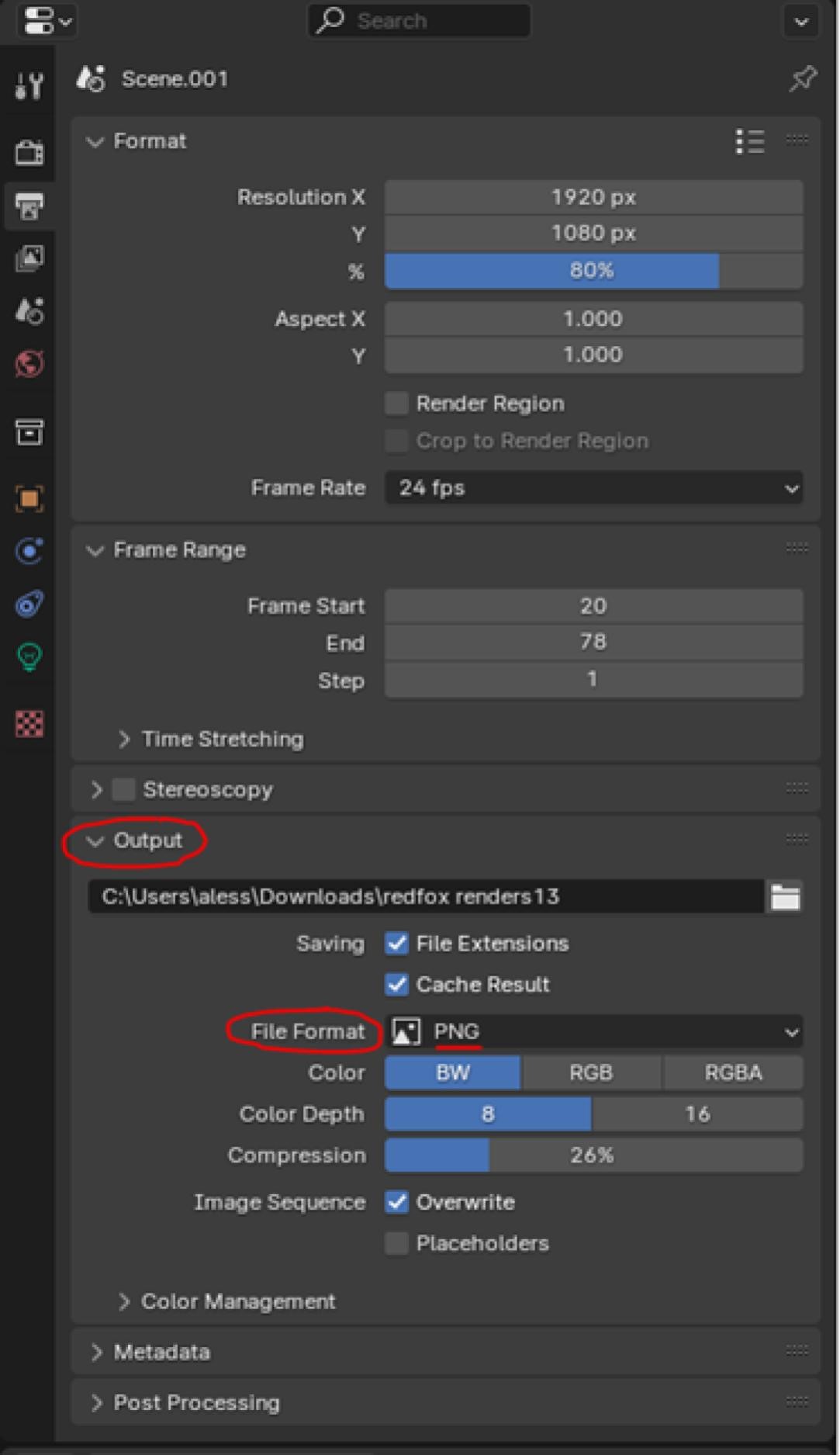
Proper settings for ‘Render Output Properties’ are essential for successfully generating a synthetic image dataset. Using Blender’s “Output Properties” panel, the following settings were used to ensure that synthetic images maintain their visual similarity to the original dataset. The resolution of the camera was set to 1920×1080 pixels, matching the original trail camera images. The “Frame Range”, which determines the length of the animation and therefore the number of images that will be produced, was set to the desired quantity. The start and end of the frame were set depending on where the animal appears and disappears from the edge of the frame. Otherwise, the generated sequence would include empty images with no animals.
Most importantly, the completed scene and animation were rendered as an image output rather than video (figure 5.8), with one PNG or JPEG image per frame. The render was also typically set to an RGB format. However, as previously mentioned, this property can be set conditionally to a B&W format if the scene includes nighttime images.
These methods were repeated across different animal classes (figure 5.9). By varying poses, exchanging HDR images, repositioning environmental elements and crafting unique scenes, it is possible to create large synthetic image datasets that are diverse and visually resemble the trail camera images. Generating diverse scenarios creates synthetic datasets better suited for machine learning research and improving model robustness.

Testing the Synthetic Dataset with Fastai
To evaluate the synthetic images generated from Blender, we conducted experiments using a custom deep learning script with Fastai and a pre-trained ResNet34 CNN. We trained and validated the model on different combinations of real and synthetic trail camera images to compare performance. This approach examines how synthetic images affect model generalization and classification accuracy. We also tested the synthetic characteristics of the images.
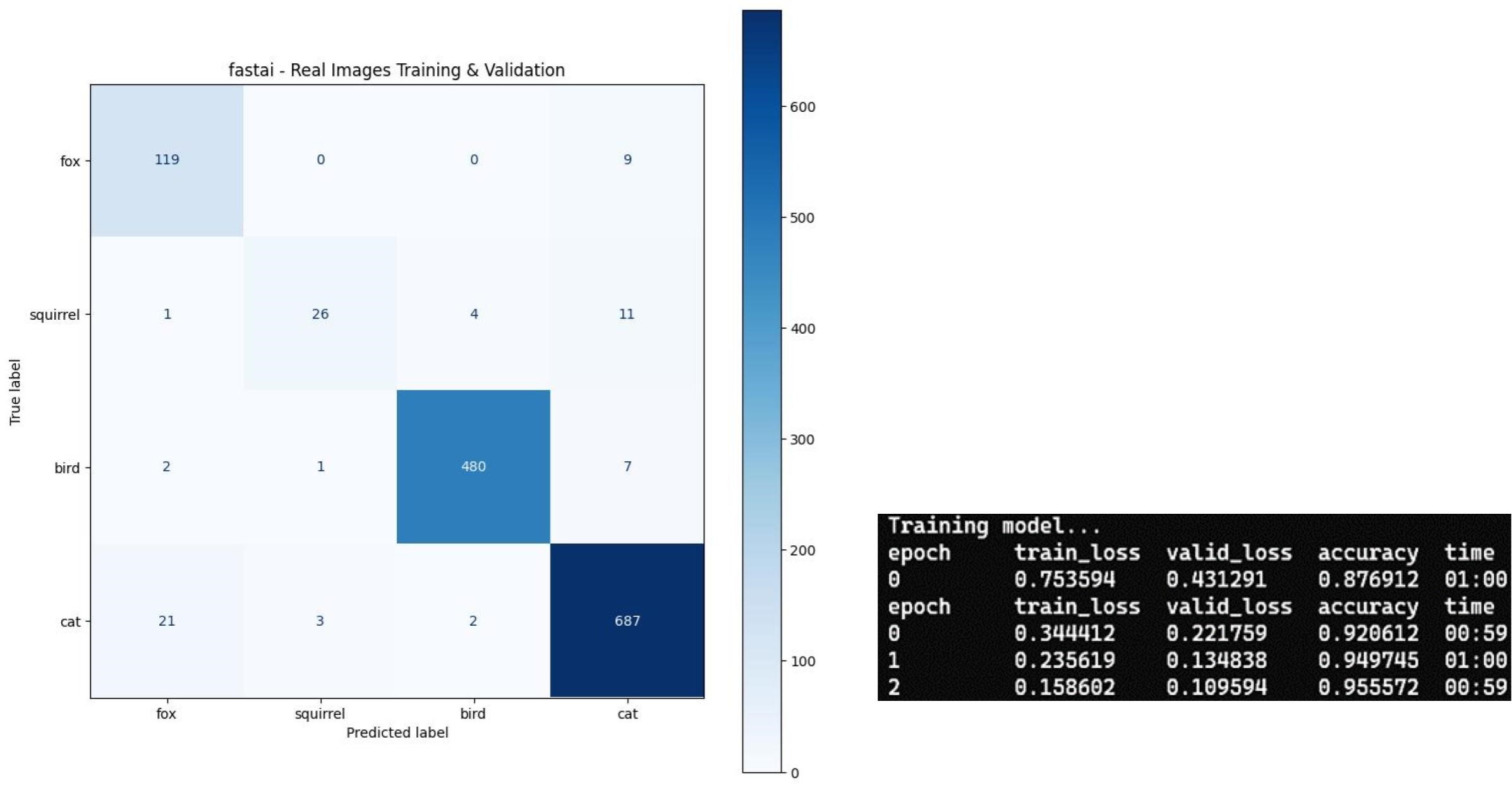
The squirrel, fox, cat, and bird classes were first tested by splitting the dataset of real trail camera images into training and validation sets. The model’s performance on this set of real images serves as a benchmark that the performance of the synthetic images can be evaluated against. In this test, we achieved an accuracy 95.6% using the ResNet34 CNN to classify the real images across four species – fox, squirrel, bird and cat (figure 5.10). (Accuracy measures the percentage of correctly classified images out of the total number of images tested.) The classification performance in each class is listed in Table 1.
|
Species |
Accuracy |
Total Images |
Accurate Classifications |
Inaccurate Classifications |
Inaccurate Breakdown |
|
Fox |
92.97% |
128 |
119 |
9 |
cat: 9 |
|
Squirrel |
61.90% |
42 |
26 |
16 |
fox: 1, bird: 4, cat: 11 |
|
Bird |
97.96% |
490 |
480 |
10 |
fox: 2, squirrel: 1, cat: 7 |
|
Cat |
96.35% |
713 |
687 |
26 |
fox: 21, squirrel: 3, bird: 2 |
Table 5.1: Classification performance of a ResNet34 CNN model on four animal species, based on analysis of 1,373 validation images. The model achieved the highest accuracy for birds (97.96%) and the lowest for squirrels (61.90%), with common misclassifications occurring between visually similar species (squirrels/foxes misclassified as cats). Overall Model Accuracy was 95.56% (1,312 correct out of 1,373 total images).
Before testing the synthetic images’ effectiveness on improving model generalization, the images were studied for their synthetic nature and image quality. This was done by configuring the model to train on only real trail camera images and validate on synthetic images alone, which involved giving the model the option to classify the synthetic images as real trail camera images in the confusion matrix (figure 5.11). This test is unique as it is not a common configuration of images in the domain of machine learning and image classification. However, this form of experimenting interestingly creates a statement on the model’s capability to differentiate between something real and artificial. The metrics may show that synthetic images are being correctly classified in terms of predictions that are specific to animal species; however, these results wouldn’t directly measure the impact of synthetic data on model generalization.
This test resulted in a model accuracy of 92.2% overall (figure 5.11). This suggests that the ‘realism’ of the synthetic images is reasonably high, or in other words, that the synthetic images are relatively similar to the real images in the context of the features that the model has learned. This could also mean that from the perspective of the model, the synthetic data closely resembles its real counterpart and given that the synthetic data was designed to closely mimic the real images, this gives an indication that the generated images achieved this goal.
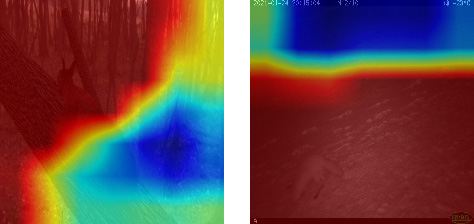
We were interested in asking whether the synthetic images may have a feature distribution similar to the real images; therefore, the model has learned features that are robust to both real and synthetic data. This can be visualized through gradient map overlays that indicate which parts of the image the model is focusing on as information to determine its classification. The model extracts features of a real fox image in a similar manner to that of a synthetic squirrel image (figure 5.12), focusing on classifying the presence of the animal in relation to its immediate surrounding environment and near proximity. Thus, although the model does not explicitly learn to distinguish between real and synthetic images, it focuses on the features that are relevant to classification tasks.

After a study of the synthetic images’ features and overall visual quality, the synthetic data was utilized to evaluate the improvement of the model’s localization accuracy. The first test of synthetic images focused on using synthetic images in the training set and real images in the validation process. The accuracy of this test was 96.4% (figure 5.13), which is higher than the 95.6% accuracy using real images alone for both training and validation (figure 5.10). This suggests that the synthetic data was highly effective at capturing key features relevant to real images. Therefore, the model can generalize well from synthetic data to real-world scenarios and suggests that the synthetic images were representative of real image characteristics. It also highlights the potential of synthetic data to enhance model training without requiring extensive real-world data.
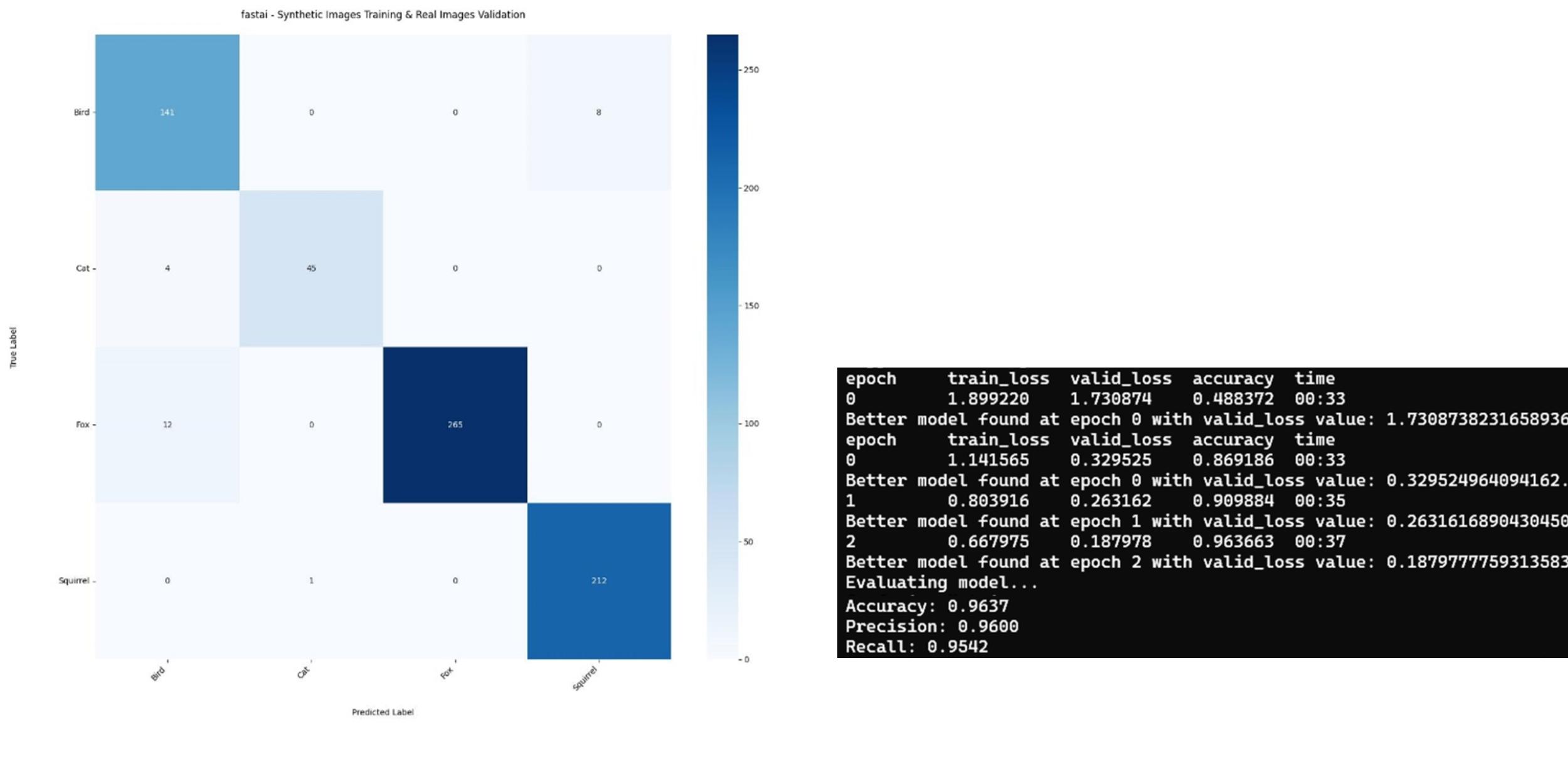
The next study focuses on using a mix of real and synthetic images in the training set and using real images alone in the validation process. Its accuracy resulted in a high value of 99.2% (figure 5.14). This configuration of images uses a balanced set of validation images at about 300 images per animal class. This is accompanied by a training set of the rest of the real images from the database for the squirrel, fox, bird, and cat species. A collection of all the generated synthetic images for these classes were added to the training set for data increase and data augmentation. In a script that utilizes fastai and a pre-trained ResNet34 model, this organization of training and validation images provides meaningful machine learning results about how synthetic images affect model classification processes.
The high accuracy of 99.2% suggests that the synthetic images, when combined with real images in the training process, play a crucial role in testing if the model’s localization accuracy improves. This implies that synthetic data effectively complements real data, enhancing the model’s ability to classify real trail camera images. The use of a balanced validation set with approximately 300 images per class ensures that the evaluation is robust and not biased towards any class, especially when the goal is to test the model with a training set of synthetic data mixed with real images. The training data has increased its diversity and covers more variations and scenarios that might not be present in the real image dataset alone. This diversity contributes to the model’s enhanced performance and ability to handle a wider range of real-world variations. It also further suggests that the synthetic images were well-designed and realistic enough to effectively train the model. This integration of synthetic and real data is particularly useful in situations where collecting large amounts of real data is challenging or expensive. Additionally, a pre-trained ResNet34 model with the fastai library provided a solid foundation for learning from both synthetic and real data. Pre-trained models come with learned features that can be fine-tuned with additional data, which contribute to the improved performance when trained with a hybrid dataset.
- Mateusz Buda, Atsuto Maki, and Maciej A. Mazurowski, “A Systematic Study of the Class Imbalance Problem in Convolutional Neural Networks,” Neural Networks 106 (2018): 249-259, https://doi.org/10.1016/j.neunet.2018.07.011. ↵
- Ibid. ↵
- Sara Beery et al., “Synthetic Examples Improve Generalization for Rare Classes,” arXiv:1904.05916v2 [cs.CV], May 14, 2019, https://arxiv.org/abs/1904.05916. ↵
- L. Gao, L. Zhang, C. Liu, and S. Wu, “Handling Imbalanced Medical Image Data: A Deep-Learning-Based One-Class Classification Approach,” Artificial Intelligence in Medicine 108 (2020): 101935, https://doi.org/10.1016/j.artmed.2020.101935. ↵
- Beery et al., "Synthetic Examples Improve Generalization." ↵
- Blender Foundation, *Blender Manual: Armatures & Rigging*, July 4, 2024, https://docs.blender.org/manual/en/latest/animation/index.html. ↵
- "Learn Rigging in 2021: List of Rigging Tutorials," *BlenderNation*, February 2, 2021, https://www.blendernation.com/2021/02/02/learn-rigging-in-2021-list-of-rigging-tutorials/. ↵
- CG Cookie, "Blender Animation Tutorials," accessed July 5, 2024, https://www.blenderguru.com/tutorials/introduction-to-rigging?rq=animation%27. ↵
- Andrew Price, "How to Animate in Blender," *Blender Guru*, accessed July 2, 2024, https://www.blenderguru.com/search?q=keyframes. ↵
- Price, "How to Animate in Blender." ↵
- Blender Foundation, *Blender Manual: Armatures & Rigging*. ↵
- Artúr I. Károly, Imre Nádas, and Péter Galambos, "Synthetic Multimodal Video Benchmark (SMVB): Utilizing Blender for Rich Dataset Generation," in *Proceedings of the 2024 IEEE 22nd World Symposium on Applied Machine Intelligence and Informatics (SAMI)* (2024): 65, https://doi.org/10.1109/SAMI60510.2024.10432848. ↵
- M. Shooter, C. Malleson, and A. Hilton, "SyDog-Video: A Synthetic Dog Video Dataset for Temporal Pose Estimation," *International Journal of Computer Vision* 132 (June 2024): 1986--2002, https://doi.org/10.1007/s11263-023-01946-z. ↵
- A. Mumuni, F. Mumuni, and N.K. Gerrar, "A Survey of Synthetic Data Augmentation Methods in Machine Vision," *Machine Intelligence Research* (2024), https://doi.org/10.1007/s11633-022-1411-7. ↵
- Shooter, Malleson, and Hilton, "SyDog-Video." ↵
- Luis A. Bolaños et al., "A Three-Dimensional Virtual Mouse Generates Synthetic Training Data for Behavioral Analysis," *Nature Methods* 18, no. 4 (2021): 378, https://doi.org/10.1038/s41592-021-01103-9. ↵
- Shooter, Malleson, and Hilton, "SyDog-Video." ↵
- Abdulrahman Kerim, Leandro Soriano Marcolino, and Richard Jiang, "Silver: Novel Rendering Engine for Data Hungry Computer Vision Models," paper presented at the *2nd International Workshop on Data Quality Assessment for Machine Learning*, August 15, 2021, https://eprints.lancs.ac.uk/id/eprint/157140. ↵
- Károly, Nádas, and Galambos, "Synthetic Multimodal Video Benchmark (SMVB)," 65. ↵
- Shooter, Malleson, and Hilton, "SyDog-Video." ↵
In imbalanced datasets, the classes that have significantly more training examples compared to other classes, which can lead to biased model performance favouring these well-represented categories.
The percentage of true positives within all positive predictions made by the model. This metric indicates model accuracy in predicting specific classes.
In machine learning datasets, classes that have fewer training examples compared to other classes, often requiring data augmentation techniques like synthetic image generation to improve model performance.
A type of Blender object used to create a skeleton consisting of a hierarchical structure of ‘bones’ that provides a framework for deforming a model’s mesh and creating movements.
Image files that contain a wider range of luminosity than standard images, used in Blender to provide realistic environmental lighting and backgrounds for 3D scenes.
A Blender configuration that defines the environmental background and lighting conditions of a 3D scene, typically using HDR images to create realistic environmental contexts.
A Blender interface where users can import and configure HDR images as the ‘World’ environment setting, which influences scene background and lighting.
The surface geometry of a 3D model in Blender, consisting of vertices, edges, and faces that define the shape and can be deformed by armatures during animation.
Markers in animation that define the start and end points of an animation sequence, specifying the values of properties like position, rotation, and scale at specific points in time.
The automatic process by which Blender calculates intermediate frames between keyframes to generate smooth transitions and fluid motions in animations.
An animation editor in Blender that provides a timeline interface for managing keyframes and animation sequences across multiple objects and properties.
A component of Blender’s Dope Sheet where users can insert keyframes and specify values for properties such as position, rotation, and scale of bones at specific frames within the timeline.
The comprehensive setup process in 3D animation that includes creating armatures and other functional elements to make models animatable, incorporating control handles and constraints for intuitive manipulation.
A branch of AI that enables computers to learn from data by analyzing patterns and trends in large datasets, using algorithms to make predictions, recognize objects, and generate new ideas based on learned information.
The main workspace in Blender where users can view and manipulate 3D models, often configured as a dual-view setup to efficiently adjust models and ensure they align with the camera’s vision.
A Blender interface panel that provides settings and controls for the specific data associated with the selected object, such as light properties (intensity, blend, bounces, radius), mesh settings, camera parameters, or other object-specific attributes depending on the type of object selected.
A Blender interface panel where users configure render settings including resolution, frame range, file format, and color mode for generating final images or animations.
