Main Body
4 Generating Synthetic Images using Stable Diffusion and Prompts
A.V. Ronquillo
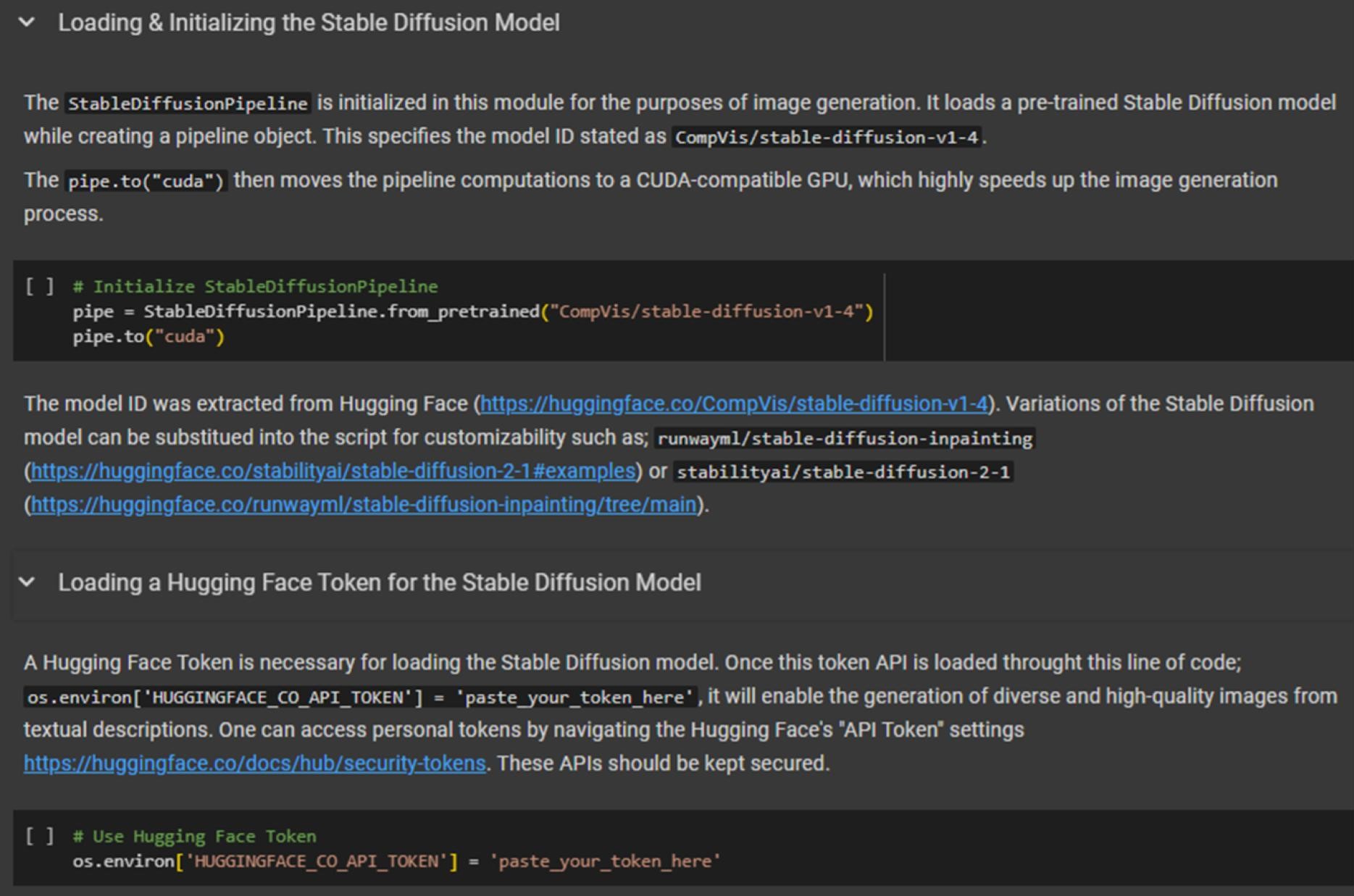
Stable Diffusion Model
Stable Diffusion is a generative model created by the founder of StabilityAI, Emad Mostaque, and it was programmed in collaboration with EleutherAI, LAION, RunwayML, and LMU Munich.[1] It became public in August 2022, and it is now one of the most reliable AI image generators. This open-source model currently has a free license and is widely used because it is highly accessible for individuals to generate images on their own computers.
Stable Diffusion builds on the foundations of generative models like Generative Adversarial Networks (GANs).[2] However, GANs typically do not have built-in features of direct text-to-image functions. The Stable Diffusion model consists of a text-to-image component which can be facilitated by powerful prompts. Although this allows for countless possibilities in generating images, StabilityAI still expects users to handle the model within ethical boundaries.[3] When Python scripts are created to utilize the Stable Diffusion model, the use of prompts in image generation can lead to more agency as the code can be implemented with adjustable parameters focusing on image quality. This further underlines the innovative and powerful nature of the model.
The model’s generative process consists of diffusion over a series of steps. It begins with an unclear and noisy image that will incrementally refine to become more like the desired image result. This involves training a denoising autoencoder to reconstruct the original image from the diffused versions, aligning the diffusion process with the goal of generating realistic images.[4] The model also utilizes a multi-scale architecture with convolutional neural networks (CNNs) for the diffusion model. This architecture allows the capture of complex dependencies across different scales and components of the image. Details about how to integrate and load the Stable Diffusion model can be found in the Stable Diffusion Jupyter Notebook (figure 4.1).
The only major challenge with this model is that it may require powerful hardware resources to run locally. However, Stable Diffusion is still a very useful open-source model characterized by various applications that can be implemented across a wide range of creative domains. It excels in generating high-quality, diverse, and realistic images across different categories like animals and objects. It can also be adapted for tasks like inpainting missing parts of images or editing existing images while maintaining visual consistency.
In the context of this project, Stable Diffusion is specifically used to augment datasets for training other machine learning models, providing synthetic but realistic variations of existing data. It is utilized as one method for generating synthetic animal images starting with real empty trail camera images. This approach is used as a strategy to counter imbalanced datasets to avoid bias in model training.
Empty Trail Camera Images
Pre-existing empty images are utilized as base images for generating synthetic animals. The ‘empty’ images are defined as trail camera images in which no animals are present within the frame of the camera (figure 4.2). The generated synthetic animals can be pasted onto these empty images using the Stable Diffusion model and prompting. A more detailed guide on how to load input images for the model can be found in the Stable Diffusion Jupyter Notebook. This method creates a type of synthetic image that features a synthetic entity on a real image. The use of real and local trail camera photographs expands on Stable Diffusion’s capability to create images with degrees of artificiality. The extent to which an image is synthesized or altered can impact the performance and training of machine learning models.[5] Blending the same empty trail camera images to generate more animals that are in the minority class introduces a way of diversifying existing conditions of the natural dataset. In this manner, this strategy attempts to improve the consistency of the synthetic data with the world observed by the trail cameras.[6]

Prompting the Generative Process
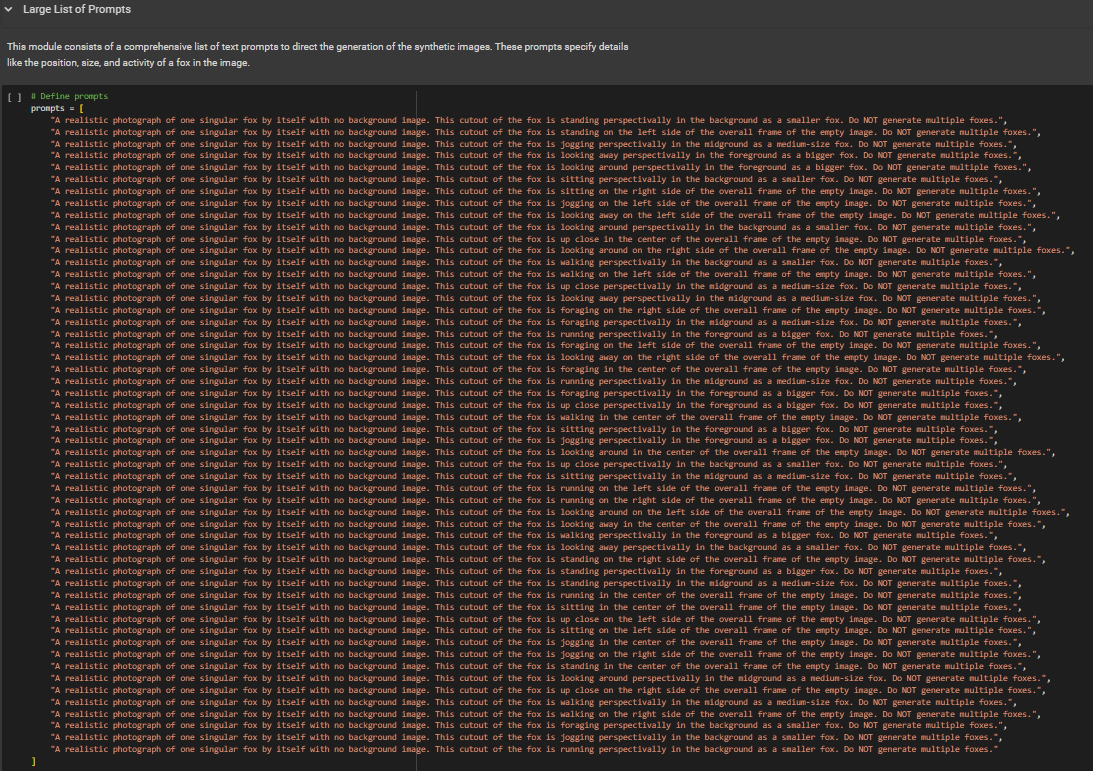
The Stable Diffusion model excels at interpreting prompts, and a large block of prompts was utilized to facilitate the processes of image generation. This strategy aims to create a large set of variations of the synthetic object’s appearance. The prompts are created by using a base prompt structure that contains interchangeable variables for stating the animal, its verb, position, location, and scale of the desired synthetic object (figure 4.3). By giving the script sets of nouns and verbs for the base prompt, every possible combination of those words can be inserted into the block of prompts for the model to interpret (figure 4.4). A detailed guide on generating a large block of prompts can be found in the Prompt Generator Jupyter Notebook. A set of samples of the results of these prompts can be previewed in the Stable Diffusion Jupyter Notebook, where documentation of errors and types of prompts are outlined.

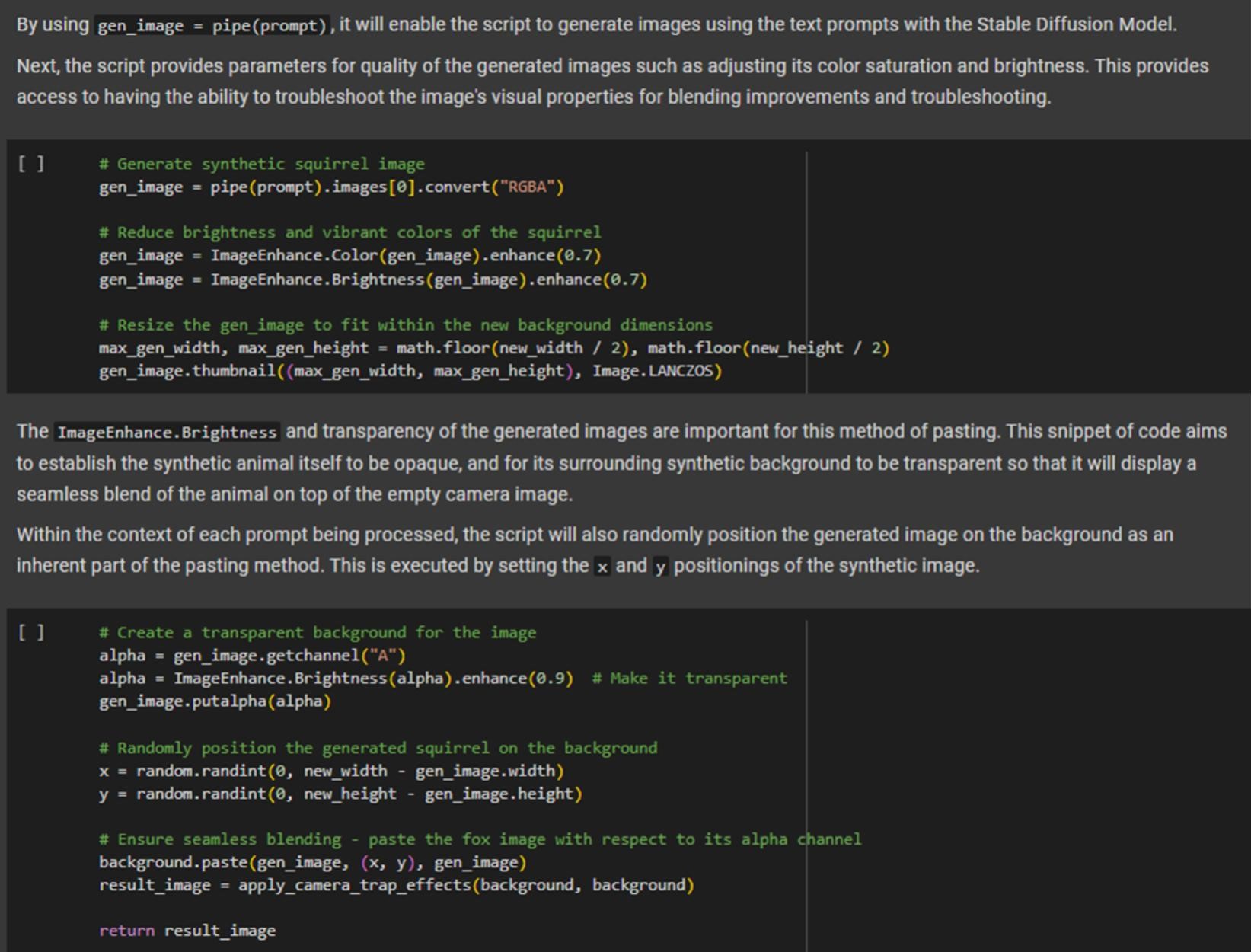
The model interprets these prompts and randomly assigns each prompt to the empty trail camera images from the local database. As the images undergo the diffusion process, the model processes selected image quality parameters included in the Stable Diffusion script (figure 4.5). These parameters are implemented as an attempt to seamlessly blend the synthetic animals with the real empty trail camera images. The methods include transparency, brightness, vibrancy, contrast, and adding motion blur. If the input is an empty image set at nighttime, the model ensures that the generated synthetic animal is also in grayscale. Essentially, this feature aims to increase the realism of the synthetic object for purposes of model training and image classification. These parameters are used to enhance the proximity of synthetic images to real animal images from the local database. Any of these settings can be implemented and customized for a wide range of tasks in image generation outside the scope of synthetic animals in wildlife research.
The outputs of the model’s diffusion process differ depending on the types of prompts, sentences, and adjustable image quality parameters. Stable Diffusion performs well when it comes to understanding the components of scale in an overall image. However, the method of pasting synthetic animals onto existing images did not yield perfect results. During the process, it was discovered that prompt specificity is highly important for generating target images. More detailed sentences will more likely yield the desired images. For instance, it is more likely that multiple foxes will be generated on the empty image if it is not specified in the prompt to create ‘one singular fox’ (figure 4.6). However, even if this were the case and one singular fox was generated, the blending of the synthetic animal did not create a seamless visual hybridity between the synthetic and real entities. This is primarily because the model struggled to adhere to the prompts, rather than the specificity of the prompt being the issue. The model habitually generated contextual backgrounds with the animals, even if it was specified in the prompt not to do so. For instance, the model continuously generated a solid bounding box with a fox (figure 4.7). An attempt to counter this was made through adjustments of the image quality parameters, such as the transparency of this box, however, this still failed to create a seamless image. More details about how this process of troubleshooting image quality and iterating on prompts are specified in the Stable Diffusion Jupyter Notebook. Although this method did not create seamlessly perfect images, it is important to document this method of image generation and automation.


Other Methods using Stable Diffusion
The Stable Diffusion Model was also used to try generating images fully from scratch. This type of image generation was attempted to test the realism of the model. The purpose was to test its capabilities to adhere to prompt instructions whilst generating images with a proper sense of scale. Because this approach does not include any pre-existing empty camera trap images, a location is specified in the prompt.
The model was asked to generate a photorealistic fox along with an accurate display of the location stated in the prompt (figure 4.8). A type of forest native to Manitoba was specified, and the model aimed to compose the animal in an accurate rendering of this environment. However, these images still do not reach the desired level of realism when it comes to their visual similarity to the real images from the original database.

The methodology of using masks was also attempted. Implementing the masks required additional steps and a new block of prompts. The Stable Diffusion script was copied and modified to test this approach. The script uses the Stable Diffusion InPaint model, which was integrated with two sets of prompts. The first set of prompts generates high-contrast masks based on the empty images from the input folder (figure 4.9). The other set of prompts generates a realistic photograph of the animal within the outlines of the mask. The motive behind this method is to eliminate the solid bounding boxes that continued to appear in the images from a previous type of base prompt in the first Stable Diffusion script (figure 4.7).
By using the masks to assist in rendering the animals, the goal was to generate seamless animal objects by adding a superimposition of the grass and foliage objects onto the image. This process was executed to increase the realism of the output images. In doing so, a method of blending the synthetic images can be tested without the use of transparency. Unfortunately, there were still issues with this script and the test was not considered successful because the second set of prompts that render the image using masks were not properly processed by the Stable Diffusion InPaint model (figure 4.9)

- Kevin Pocock, "The Creators of Stable Diffusion: An Inside Look," *PC Guide*, updated August 11, 2023, https://www.pcguide.com/apps/who-made-stable-diffusion/. ↵
- Vasco Meerman, "History and Literature on (Stable) Diffusion," *Medium*, August 16, 2023, https://medium.com/@vasco-dev/history-and-literature-on-latent-stable-diffusion-dbca69fd54d5. ↵
- Pocock, "The Creators of Stable Diffusion." ↵
- Meerman, "History and Literature on (Stable) Diffusion." ↵
- Sara Beery et al., "Synthetic Examples Improve Generalization for Rare Classes," *arXiv:1904.05916v2 [cs.CV]*, May 14, 2019, https://arxiv.org/abs/1904.05916. ↵
- Ibid. ↵
A generative model created by StabilityAI that uses diffusion processes to generate images from text prompts. It is an open-source model that can generate high-quality, diverse, and realistic images across different categories.
Ludwig Maximilian University of Munich, one of the academic institutions that collaborated in the development of Stable Diffusion.
A machine learning architecture consisting of two neural networks competing against each other in a game-theoretic framework. The generator network creates synthetic data (such as images) from random noise, while the discriminator network attempts to distinguish between real and generated data. Through this adversarial training process, the generator becomes increasingly skilled at producing realistic synthetic content that can fool the discriminator. GANs are widely used for generating images, videos, and other data types, though they typically do not have built-in text-to-image functions like more recent models such as Stable Diffusion.
A capability of Stable Diffusion that allows the model to generate images based on textual descriptions or prompts, distinguishing it from traditional GANs that typically lack this direct text-to-image functionality.
The generative process used in Stable Diffusion that begins with an unclear and noisy image and incrementally refines it to become more like the desired image result through a series of denoising steps.
A neural network component used in Stable Diffusion that is trained to reconstruct original images from diffused (noisy) versions, enabling the model to generate clear images from random noise through iterative refinement.
The architectural approach used in Stable Diffusion that employs convolutional neural networks (CNNs) at different scales to capture complex dependencies across different scales and components of images.
A type of neural network architecture particularly effective for image processing tasks. CNNs use convolutional layers to detect features in images and are commonly used in models like ResNet34 and as part of the Stable Diffusion architecture.
A technique for filling in missing parts of images or editing existing images while maintaining visual consistency. Stable Diffusion includes an InPaint model for this purpose.
A branch of AI that enables computers to learn from data by analyzing patterns and trends in large datasets, using algorithms to make predictions, recognize objects, and generate new ideas based on learned information.
The process of teaching a machine learning algorithm to make accurate predictions by feeding it labeled data examples, allowing the model to learn patterns and relationships that enable it to classify or predict outcomes on new, unseen data. This involves adjusting the model's internal parameters through iterative exposure to training data until the model achieves satisfactory performance.
The process of seamlessly combining synthetic animals with real background images to create realistic composite images, often involving adjustments to transparency, brightness, vibrancy, contrast, and motion blur.
In machine learning datasets, classes that have fewer training examples compared to other classes, often requiring data augmentation techniques like synthetic image generation to improve model performance.
An image quality parameter that adjusts the intensity and saturation of colors in synthetic objects to better match the color characteristics of the background image.
The simplest image analysis technique offered by YOLOv8, image classification involves identifying what class the objects within a given image belong to and provides the class name and confidence score. This technique does not identify the location of the predicted objects within a given image.
The seamless integration of synthetic and real elements in a composite image, where the boundary between artificial and authentic components is not easily distinguishable.
